🌌 Operating Systems: Three Easy Pieces
Remzi H Arpaci-Dusseau, Andrea C Arpaci-Dusseau
chapter 44. Flash-based SSDs
🔦 Flash-based SSD란?
플래시 메모리를 기반으로 한 Non-Volatile 저장장치
CPU, RAM, 트랜지스터로 구성되어 있고 주요 쟁점은 삭제 비용과 수명 단축 문제를 해결하는 것이다.
- SSD의 구성 요소
- 플래시 칩: 영구 저장을 위한 주요 구성 요소
- 휘발성 메모리(SRAM 등): 데이터 캐싱, 버퍼링 및 매핑 테이블을 위한 메모리
- 제어 로직 : SSD의 작업을 제어하고 조정하는 역할
FTL(Flash Translation Layer)을 통해 LBA와 PBA를 매핑하며,
클라이언트의 읽기/쓰기 요청을 처리하고 이를 내부 플래시 연산으로 변환한다.
- 플래시 칩의 구성
플래시 칩은 bank/plane으로 구성된다. bank는 block과 page로 접근할 수 있다.
(* RAID에서 쓰는 block이나 virtual memory에서 쓰는 page 용어와는 다름)
EX)
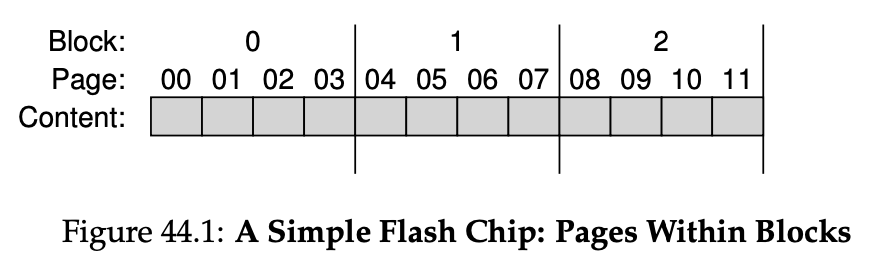
flash plane 안에 3 blocks이 있고 블록안에 4 pages가 있는 모습
- 플래시 칩의 명령어(3)
- Read
페이지 단위로 수행되며 페이지 번호 지정으로 2 or 4KB 크기의 페이지를 빠르게(수십 μs) 읽을 수 있다.
이전 요청의 영향을 받지 않아 random acess가 가능하다. - Erase
블록 단위로 수행되며 속도가 느리다(ms).
특정 페이지에 데이터를 쓰려면 먼저 해당 페이지가 포함된 블록 전체를 지워야 한다. - Program
페이지 단위로 수행되며 지운 블록에 데이터를 저장하는 과정이다.
초기화(1)된 페이지에서 일부 비트를 0으로 변경해 데이터를 저장한다.
읽기보다 느리지만 지우기보다 빠르다(수백 μs).
상태 변화 : INVALID → Erase → ERASED → Program → VALID
Read는 상태에 영향을 주지 않지만 VAILD 상태에서만 읽을 수 있다.
Overwrite가 불가능하므로 데이터를 쓰려면 Erase 후 다시 써야 한다.
EX)

page 0만 쓰고 싶어도 블록 전체를 erase 해야 해서 page 1, 2, 3의 데이터가 사라짐
그래서,
플래시 칩은 read에 뛰어나고 HDD와 달리 seek time, rotate time이 없어 랜덤 읽기에 유리하다.
write에서는 필요한 데이터를 다른 곳에 옮기고 블록 전체를 지운 후에 데이터를 써야 하는데,
이 지우는 과정의 cost가 크고 느리며 플래시 칩의 수명 단축(wear out)도 만든다.
→ 플래시 기반 스토리지 시스템에서는 쓰기 성능과 신뢰성(reliability)이 핵심 문제가 된다.
- 플래시 칩의 성능 특성
- Read 속도 : 셀당 저장 비트 수와 관계없이 일정하게 빠름, 수십 마이크로초(μs)
- Program 속도 : 셀당 저장 비트 수가 많을수록 더 느려짐
EX) SLC(200μs) > MLC > TLC - Erase 속도 : 수 밀리초(ms) 단위의 가장 큰 성능 cost를 가져 병목이 됨
- 플래시 칩의 신뢰성(reliability)
- 마모(Wear-out) : 반복적인 P/E(Program/Erase) 과정에서 성능이 저하되어 0, 1 비트 구별이 어려워짐
- 오류 전파(Disturbance) : 특정 페이지를 읽거나 쓸 때 인접한 페이지의 비트가 의도치 않게 바뀌는 문제
→ SSD 컨트롤러에 오류 수정 코드(ECC) 필요
- FTL의 성능과 신뢰성 목표
- multi 플래시 칩 : 여러 플래시 칩을 병렬로 사용하여 쓰기 성능 향상
- 쓰기 증폭(Write Amplification) 감소
↳ 클라이언트가 요청한 것보다 더 많은 쓰기 작업을 수행하게 되는 것 - 마모(Wear Out) 문제 → 웨어 레벨링(Wear Leveling)으로 플래시 블록에 쓰기를 고르게 분배
- Program Disturbance 문제 → 지워진 블록 내에서 페이지를 순서대로 Sequential-Programming해 교란 최소화
- A Log-Structured FTL
현재 대부분의 FTL은 Log-Structed로, Logging 방식을 이용한다.
EX)
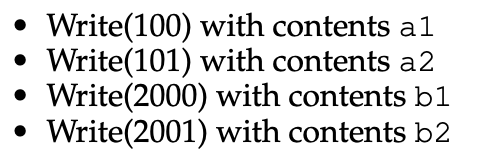
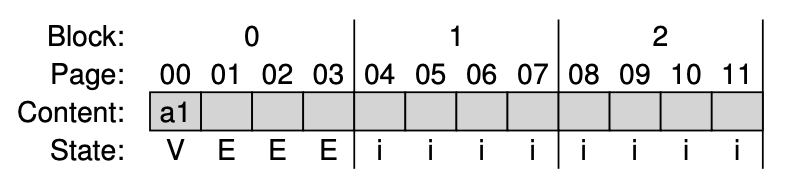
1. 초기 상태 :
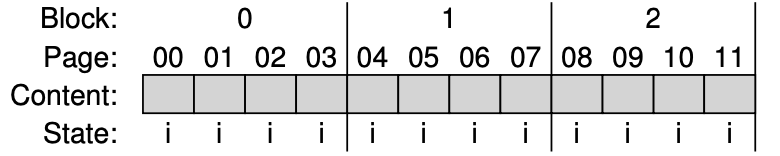
2.
- 첫 쓰기 요청에서 FTL은 해당 논리 블록을 물리적 블록 0에 기록하기로 결정한다.
- 물리적 블록 0은 INVALID이므로 먼저 Erase를 해야 한다.
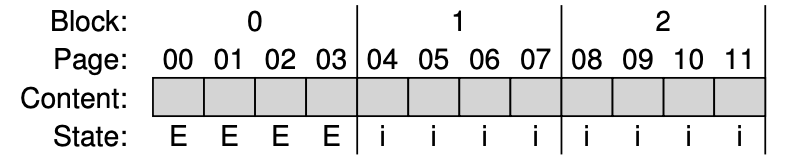
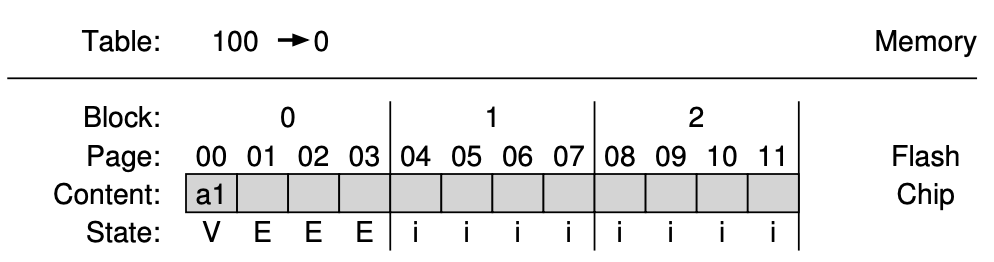
3.
- 블록 0을 지운 후 페이지를 순차적으로 기록한다(교란 문제 최소화).
- 논리 블록 100의 데이터는 물리적 페이지 0에 기록된다.
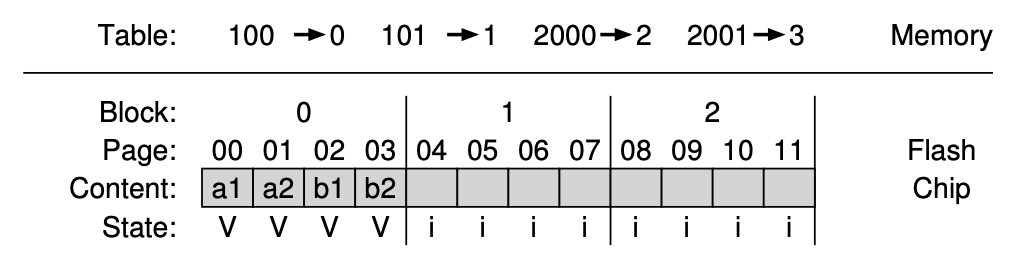
4.
- 논리 블록 100을 읽으려면 매핑 테이블을 사용해 논리 블록 100을 물리적 페이지 0으로 변환해야 한다.
- Read - 매핑 테이블로 논리 블록 주소를 물리적 페이지 번호로 변환하여 데이터를 읽는다.
- Write - 빈 페이지를 찾아 데이터를 기록하고 매핑 테이블에 매핑을 저장한다.
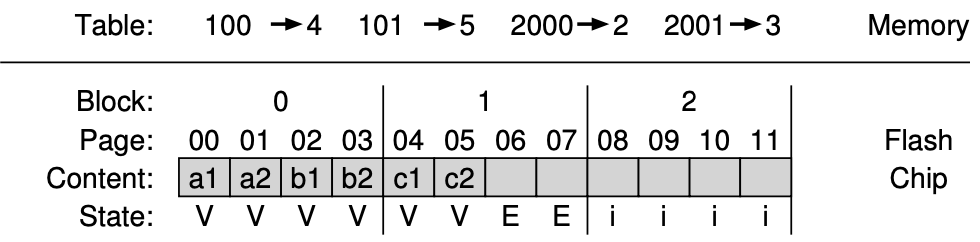
5.
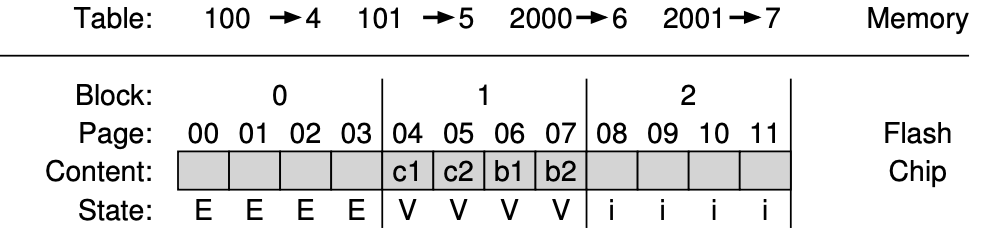
- 나머지 Write 101, 2000, 2001 이후 장치의 상태는 다음과 같다.
단점 : GC Performance Overhead, Mapping Table Space Overhead
- Garbage Collection Performance Overhead
GC에서 쓰기 작업이 많이 일어나서 Overhead가 발생한다.
EX)
현재 블록 0 : Dead - Page 0, 1
Live - Page 2(logically 2000), 3(logically 2001)
블록 0의 Dead Page를 회수하기 위한 Step
- Live Data 읽기 : 블록 0에서 Live Page(2, 3)를 읽음
- 새로운 블록에 저장 : 읽어온 데이터를 Log 끝에 기록
- 블록 0 Erase : 새로운 데이터를 쓸 수 있도록 공간 확보
- Mapping Table Space Overhead
각 4KB 페이지마다 매핑 항목이 필요하므로 Space Overhead가 발생한다.
EX) 1TB SSD에서 4KB 페이지당 4바이트 크기 매핑 엔트리가 필요하다고 가정하면 1GB 매핑 테이블이 필요함
1. Block-Based Mapping
각 페이지마다 매핑 정보를 저장하지 않고 각 블록마다 하나의 포인터만 유지한다.
매핑 정보의 크기가 블록 크기와 페이지 크기의 비율만큼 줄어든다.
EX) Virtual Memory에서 페이지 크기를 크게 하는 것과 유사(VPN bit를 줄이고 Offset을 활용)
단점 : 블록보다 작은 쓰기에서도 기존 블록의 유효한 데이터를 모두 읽어 새로운 블록에 복사하며 쓰기 증폭이 일어난다.
2. Hybrid Mapping
- Switching Merge
로그 페이지 전체가 Invalid한 경우, 추가적인 데이터 이동 없이 로그 페이지를 모두 데이터 페이지로 전환하면 된다.
EX) 논리 블록 0, 1, 2, 3이 새로운 로그 블록(0)에 기록되면 FTL은 이 로그 블록(0)을 데이터 블록으로 전환하고 해당 블록 전체를 가리키는 단일 블록 포인터를 매핑 테이블에 저장한다. 기존 블록(2)은 삭제(Erase) 후 새로운 로그 블록으로 사용 가능하다. - Partical Merge
로그 블록의 일부 페이지만 유효한 경우에 유효 데이터만 읽어 새 블록을 만든다. - Full Merge
여러 블록에 흩어진 데이터를 하나의 블록으로 통합하기 위해 모든 로그 페이지를 읽는다.
3. Page Mapping + Caching
Locality를 기반으로 캐싱 기법을 잘 활용하면 메모리 사용량을 줄이면서 성능을 유지할 수 있음
하지만 필요한 매핑 정보를 메모리에 담지 못하면 성능이 크게 저하될 수 있음
더 나쁜 경우, 새로운 매핑 정보를 저장하기 위해 기존 매핑 정보를 내보내야 하는 상황 발생
- SSD vs HDD
SSD는 기계적인 부품이 없어 데이터 접근 속도가 훨씬 빠르다.
SSD에서는 내부 FTL 설계로 얼마나 성능 저하 요인을 잘 숨기는지(GC, 쓰기 증폭 등)가 핵심이 된다.
- Performance? 랜덤 I/O 작업에서는 SSD가 매우 압도적으로 우수하다.
- SSD : 수십~수백 MB/s
- HDD : 고급형 모델조차 2MB/s 정도
- Cost? 하지만 HDD가 bit per cost에서 훨씬 저렴하기 때문에 상황에 따라 선택하면 된다.
- Hybrid? Hot Data는 빠른 SSD에 저장하고 Cold Data는 저렴한 HDD에 저장하여 비용을 절감하고 성능은 유지한다.
'My Laboratory' 카테고리의 다른 글
| [NVMeVirt] implementation of DFTL #1 (0) | 2025.09.04 |
|---|---|
| Paper Review : NVMeVirt: A Versatile Software-defined Virtual NVMe Device (0) | 2025.08.08 |
| Paper Review : DFTL(Demand-based Flash Translation Layer) (3) | 2025.07.28 |
| [MQSim] 변수 변경에 따른 성능을 평가해보자 (4) | 2025.01.23 |
| [MQSim] Intro (2) | 2025.01.23 |