🌟 Memory Computing and Computer Architecture Lab
NVMeVirt Weekly Study
- 이전글
[NVMeVirt] Implementation of DFTL #3 : write
🌟 Memory Computing and Computer Architecture LabNVMeVirt Weekly Study- 이전글 [NVMeVirt] implementation of DFTL #2 : read🌟 Memory Computing and Computer Architecture LabNVMeVirt Weekly Seminar [NVMeVirt] implementation of DFTL : init & rm🌟 Memo
wifiaircat.tistory.com
idea1. dftl_conv_ftl.h 파일에 전역변수 선언하여 main.c에서 받아 초기화 -> dftl_conv_ftl.c 파일에서 카운트하자
idea2. dftl_log.txt : txt 파일로 뽑자
idea3. 전역변수 선언한 io.h 파일을 만들어 io.c와 dftl_conv_ftl.c에 포함 -> io_worker_init에 초기화
-> 모두 실패
idea2는 dmesg가 너무 많아서 모두 기록하지 못하고 로그가 짤렸다...
idea1과 idea3은 총제적으로 아래 사유였다...
fio 작업 끝나는 시점, 시작하는 시점 찾아서 초기화 하겠다고 진짜 고생함... 근데 그런 게 없다?


이제 진짜입니다...

dftl_conv_ftl.h와 dftl_conv_ftl.c에서 extern 변수를 선언해주는 것은 이전과 같다.
<dftl_conv_ftl.c>
atomic64_t dftl_hit = ATOMIC64_INIT(0);
atomic64_t dftl_miss = ATOMIC64_INIT(0);
<dftl_conv_ftl.h>
extern atomic64_t dftl_hit;
extern atomic64_t dftl_miss;
get_cmt_ent에서 dftl_hit과 dftl_miss를 카운트 해주는 것도 이전과 같다.
/* cache hit path */
for (int i = 0; i < CMT_SIZE; i++) {
if (conv_ftl->cmt[i].valid && conv_ftl->cmt[i].lpn == lpn) {
/* case of cache hit */
NVMEV_DEBUG("[DFTL] cmt hit: lpn=%llu\n", lpn);
atomic64_inc(&dftl_hit);
/* victim policy : LRU */
conv_ftl->cmt[i].last_access = get_current_time();
return conv_ftl->cmt[i].ppa;
}
}
/* cache miss path */
NVMEV_DEBUG("[DFTL] cmt miss: lpn=%llu\n", lpn);
atomic64_inc(&dftl_miss);
얘네들이 새로 만든 함수...
<main.c>
static int dftl_stats_show(struct seq_file *m, void *v)
{
u64 hit = atomic64_read(&dftl_hit);
u64 miss = atomic64_read(&dftl_miss);
u64 tot = hit + miss;
u64 pct100 = tot ? hit * 10000 / tot : 0;
seq_printf(m, "hit=%llu miss=%llu ratio=%llu.%02llu%%\n",
hit, miss, pct100/100, pct100%100);
return 0;
}static int dftl_stats_open(struct inode *inode, struct file *file)
{
return single_open(file, dftl_stats_show, NULL);
}static ssize_t dftl_stats_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
char cmd[8];
if (count > 7) count = 7;
if (copy_from_user(cmd, buf, count))
return -EFAULT;
cmd[count] = '\0';
if (strncmp(cmd, "reset", 5) == 0) {
atomic64_set(&dftl_hit, 0);
atomic64_set(&dftl_miss, 0);
}
return count;
}static const struct proc_ops dftl_stats_fops = {
.proc_open = dftl_stats_open,
.proc_read = seq_read,
.proc_release = single_release,
.proc_write = dftl_stats_write,
};
NVMeV_init 함수와 NVMeV_exit 함수에 각각 (1), (2)로 초기화와 제거 해주면 된다...
(1) proc_create("dftl_stats", 0666, NULL, &dftl_stats_fops);
(2) remove_proc_entry("dftl_stats", NULL);
이렇게 하면 NVMeVirt 실행 중에도 다른 터미널을 열어서 간편하게
명령어로 hit과 miss ratio를 확인할 수 있다는 것이다~.
이후 간단한 테스트로 작동이 잘 되는지 확인을 해주고 실험 설계로.
CMT가 커버 가능한 용량을 먼저 계산한다.
CMT 커버 범위 = CMT_SIZE × PAGE_SIZE × SSD_PARTITIONS
사실 이 식을 도출해내기까지도 많이 헤맸다...
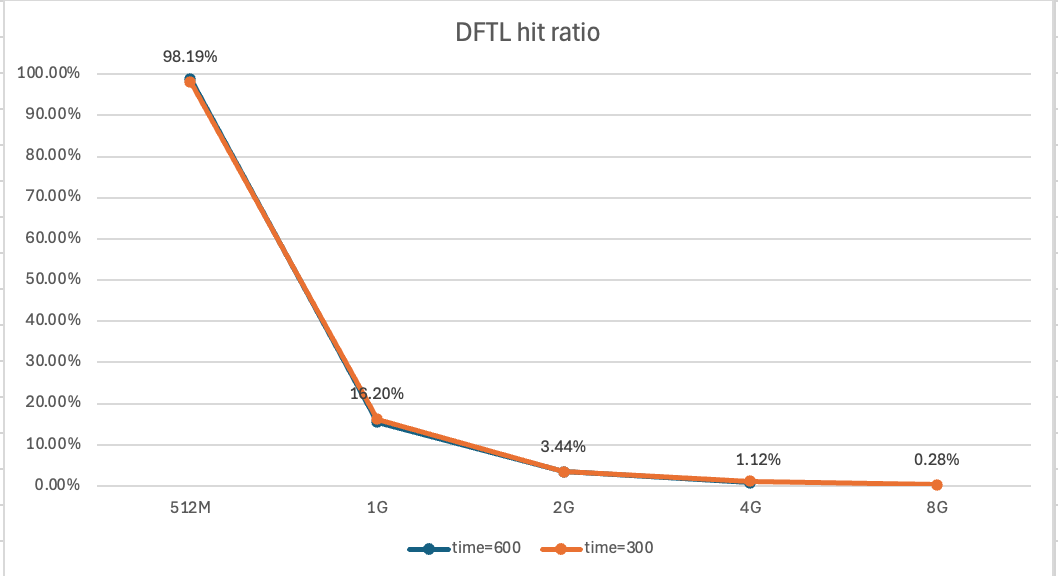
안물안궁이지만 이게 내가 처음으로 그렸던 실험 결과 그래프인데
이게 예상대로 나오지 않아서 왜 그럴까 가정들을 세웠다.
내가 알고 있는 변수가 아니라 다른 페이지 사이즈를 사용하고 있는지,
fio의 locality나 active working set의 영향이 있는지,
partition이나 channel 수가 곱해지고 있는 것인지 등등
실험을 돌려가면서 검증하고 하나씩 제거해나갔다.
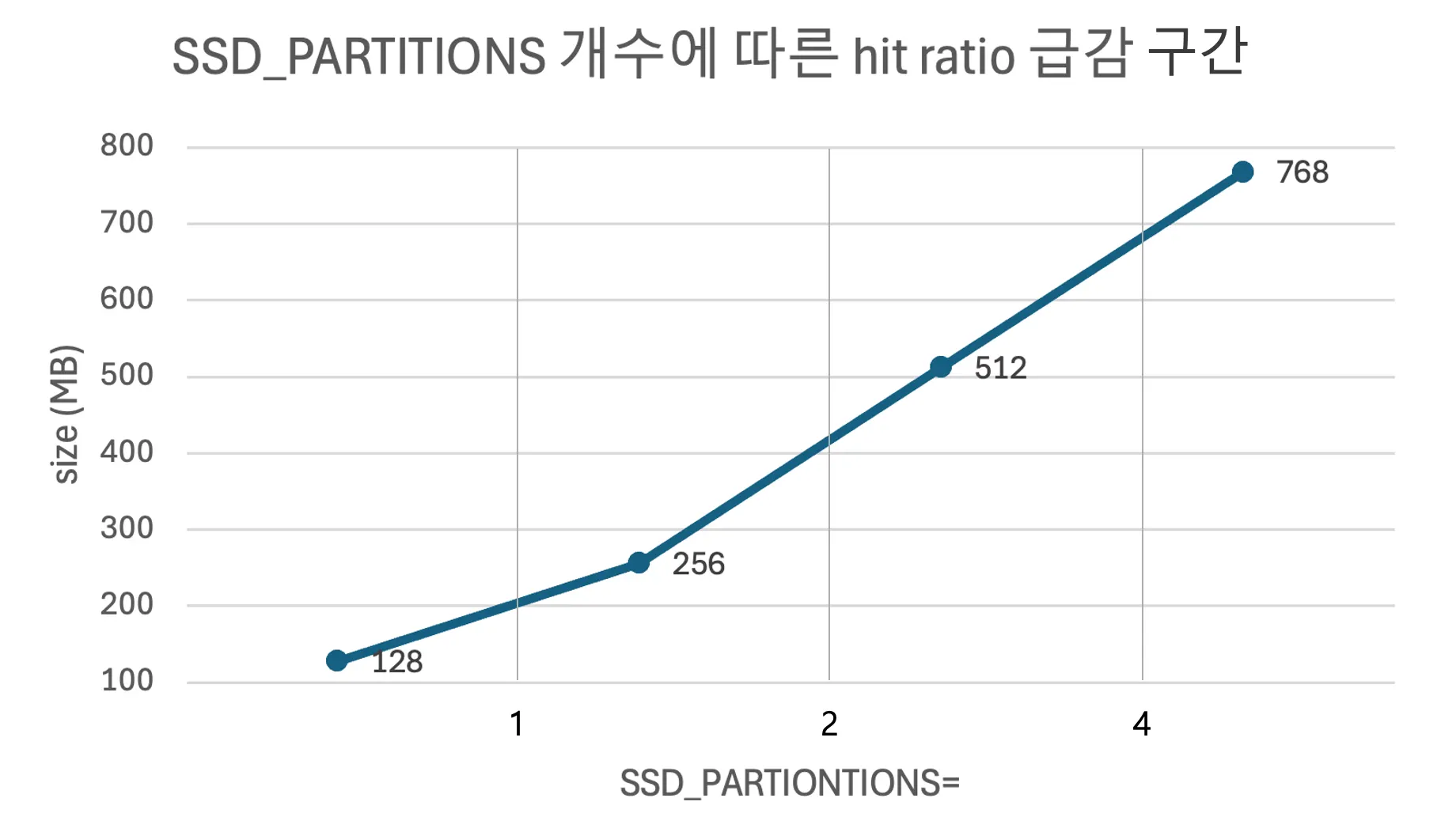
그래서 결국 SSD partition 수가 영향을 주고 있었다는 사실을 알아냄.
기타 주의사항 : randread, norandommap 옵션 주기

Coverage 넘어가자마자 hit raito가 1/2씩 감소하는 예쁜 그래프가 완성 되었다. 평가 완료~
'My Laboratory' 카테고리의 다른 글
| [NVMeVirt] Implementation of DFTL #3 : write (0) | 2025.09.24 |
|---|---|
| Doc Review : 소프트웨어(s/w) 에러정정코드(ecc)를 이용한 낸드 플래시에서의 데이터 입출력 방법 및 그 방법을 이용한 임베디드 시스템 (0) | 2025.09.24 |
| [NVMeVirt] implementation of DFTL #2 : read (1) | 2025.09.10 |
| [NVMeVirt] implementation of DFTL #1 (0) | 2025.09.04 |
| Paper Review : NVMeVirt: A Versatile Software-defined Virtual NVMe Device (0) | 2025.08.08 |